python爬虫
1538 浏览 7 years, 9 months
4.2 伪装成浏览器访问网页
版权声明: 转载请注明出处 http://www.codingsoho.com/有些网页,如果不是从浏览器发起的访问,它会拒绝响应。我们可以自己来写报头,然后发送给网页浏览器,它会认为你是一个正常的浏览器,这样就可以访问了。
import urllib2
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
webheader = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
proxy = urllib2.ProxyHandler({'http': '[127.0.0.1:8888](127.0.0.1:8888)'})
opener = urllib2.build_opener(proxy)
urllib2.install_opener(opener)
request = urllib2.Request(url,headers=webheader)
webPage=urllib2.urlopen(request)
data = webPage.read()
print(data)
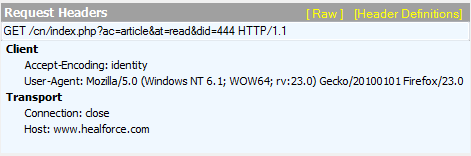
可以添加更多的header,从Fiddler截图中可以看到Client里的Header内容增加了。返回内容没有变化
import urllib2
url = "[http://www.healforce.com/cn/index.php](http://www.healforce.com/cn/index.php)?ac=article&at=read&did=444"
webheader = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
#'Accept-Encoding': 'gzip, deflate',
'Host': 'www.douban.com',
'DNT': '1'
}
proxy = urllib2.ProxyHandler({'http': '[127.0.0.1:8888](127.0.0.1:8888)'})
opener = urllib2.build_opener(proxy)
urllib2.install_opener(opener)
request = urllib2.Request(url,headers=webheader)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0')
request.add_header('Accept-Encoding','gzip, deflate')
webPage=urllib2.urlopen(request)
data = webPage.read()
